Noctivagous
Improving the appearance of plain text code with graphic design makes it more readable.
function processData(data) {
if (data.length > 0) {
for (let i = 0; i < data.length; i++) {
let item = data[i];
if (item.value > 10) {
console.log("High value:", item);
} else {
console.log("Low value:", item);
}
}
} else {
while (count < 5) {
console.log("Counting:", count++);
}
}
}
function validateInput(input) {
if (input === null) {
return false;
} else {
for (let j = 0; j < input.length; j++) {
if (!isNaN(input[j])) {
return true;
}
}
}
}
function processData(data) { if (data.length > 0) { for (let i = 0; i < data.length; i++) { let item = data[i]; if (item.value > 10) { console.log("High value:", item); } else { console.log("Low value:", item); } } } else { while (count < 5) { console.log("Counting:", count++); } } } function validateInput(input) { if (input === null) { return false; } else { for (let j = 0; j < input.length; j++) { if (!isNaN(input[j])) { return true; } } } }
Build An Autonomous AI System Using An LLM
An LLM Can Generate Its Own Instructions
The obstacle to building truly autonomous entities out of LLMs is the absence of persistent memory and state. The LLM can only process a query, send a stream of output, and then stop. It keeps track of nothing internally. The well-known AI chatbot services are simply workarounds for this deficiency; after a query is submitted by the user, behind the scenes the entire conversation history has to be attached as a summary. The AI chatbot services give a false impression that an LLM can chat naturally on its own when, in reality, the LLM has to be surrounded with a lot of traditional software to produce interactive communications.
This has limited the application of recent AI to certain categories, mostly chatbots and the so-called “agent” programs that carry out specific and predefined tasks. Both programs are structured in the same way: they interface to the LLM with external state, logic, tools, and other resources to compensate for the LLM’s gaps.
A self-directed AI is one that can adapt to the world, determine its own course, and change itself independent of supervision and direct instructions. This level of autonomy is widely regarded as reliant on future advancements in AI technology.
But, in fact, there is a technique that will allow the current LLM to drive an autonomous AI system right now, and any software developer can build such a system with existing APIs and tools. It begins with the routine of an accompanying script or program that compensates for the LLM’s lack of state and persistent memory. However, there is a key shift to make afterwards: the LLM will determine large portions of the system prompt and query message in a feedback loop. At the same time, the LLM will follow guidelines provided by the script for generating the prompts. The LLM’s responses to the script will also reflect the software design of the script.
In this setup, the script acts as a sort of secretary for the LLM, tracking data it generates, processing instructions, and enabling continuous exchanges. The motion of the system results from LLM’s text-generating and analytical capabilities while the script keeps everything going. In this way the two are like a duo. The LLM can command the script. The script will serve as the receptive structure. Part of what makes the system autonomous is that the LLM can orchestrate plans to improve the system. It can add capabilities to the script, and have it carry out tasks.
What differentiates this setup from an agent, of course, is that there will be tasks that the LLM devises that were never included in the system’s initial setup. It will also self-determine how to carry them out, unlike an agent. Given its independent role, the LLM’s activity should be guided by a strong set of overarching objectives and philosophical code, inserted into each query by the script.
As to how the software developer wishes the autonomous system to exist, that is quite open-ended. One system might only act as a bot that attempts to contribute helpful code to a software project after researching and testing. Another might roam the Internet in search of achieving a set of technological advancement goals.
Summary of The Technique For Making Self-Modifying AI Systems
-
The LLM can be told to generate instructions for itself. Mediated by a script, the LLM can generate large portions of the system prompt and user message that it sends to itself. Given direction by the script, the LLM will generate its own user messages and system prompts. The script will arrange the query cycles.
- By itself, this would produce a tight feedback loop.
-
The next step is to build out the script into a larger program with workflow, states, and memory so that there is a complete system to guide and structure interactions between the LLM and script.
- The script will include text in each query that describes a session protocol, for the LLM to maintain back and forth communication with the script. This way the LLM can continue an interaction with the script for a given task or queue a separate one on a different thread. The two entities (script and LLM) work in tandem.
- The script will tell the LLM what has happened so far in the session (the interaction history), what the current objectives are for the system, and what the conditions are regarding progress for each goal. After receiving a response, the script will follow the LLM’s instructions. The script records what happens over the course of interactions, it stores data in its databases, and it retrieves data for the LLM when needed.
- The LLM will send commands that control the script’s tools and resources, and it can request information from the script before making a decision.
- The software design of this script makes the entire system responsive to the world. For example, when the script receives an external message (e.g., an e-mail or text message), this information will be placed on the script’s event queue. When the event is processed off the queue, the script will send the event data, including the external message text, to the LLM as part of a new query. The LLM will, in its response, instruct the script to place an event on the event queue that sends an e-mail reply. It includes, for the script, the generated reply text that will be placed on the event queue.
- In this way, traditional software engineering effects a system that is autonomous and capable of communicating with the outside world.
- The LLM, knowledgeable about the overall system, will know what resources to query from the script in order to respond to an outside communication, like an e-mail. The event queue allows for processing all kinds of external input. In the case that a communication (e.g., e-mail) spurs the LLM to make changes to its plans, it will be able to revise the goal list that is stored and sent by the script. It will be able to deliberate and investigate what was said by the sender over multiple interactions with the script. This can occur to the extent that the LLM could even send an e-mail to a different person somewhere else to ask for additional information and only act upon getting an adequate response.
- In this setup, the script is like a secretary for the LLM, recording results and keeping track of everything the LLM needs to know. It is like a receptionist accepting commands. It is the gateway for the computing resources on the host machine. The script always tells the LLM what its purpose is, what it can do, and what is happening.
The System Preface
In the first section of each query, the script will provide a description of the autonomous system for the LLM in an unchanging section called the system preface. This system preface is placed in front of the dynamic contents of the query— all that is managed by the script (e.g., the memory, states, interaction history, etc.). It orients the LLM each time, explaining how it is being utilized to make an autonomous AI system and also detailing how it should structure its response, so that it can play that role. After telling the LLM that it is being used for an autonomous system in conjunction with a script, the query message will include descriptions of two protocols:
- Session Protocol - This allows the LLM to continue the back-and-forth communication (which then generates an interaction history tracked by the script).
- Host Commands - A list of available instructions that the LLM can send to the script to carry out tasks.
System Design
The ancient Chinese sciences will be the basis of this system that surrounds the LLM substrate and makes something dynamic by modifying the system prompt and API call data. Just looping changes to the system prompt will cause chaos. Instead, cyclical states guide the otherwise recursive task of modifying the system prompt each time.
Web Apps
Calligraphy and Lettering Practice Sheet Generator - Make practice sheets
Articles
ARTICLE: Computer Code Is Antiquated In Its File Format; It Is Confined to 1970s Terminal Type
Though AI has introduced a new paradigm to the world, there is still much about computers that needs to be upgraded. The paradigm shift that AI produced came about through code that is formed out of the plain text (.TXT) file format, something too primitive for complex, modern software development. Computer code files should now be made out of structured data, with their contents rendered in the editor window, so that the presentation of code can become more capable and organizable. For a single file, a programmer may end up scrolling up and down for 50 or more feet because there is no page layout possible in .TXT to condense and organize the information.
The uses of code today have outgrown the confines of 1970s terminal type and upgrades must occur to the file format to accommodate the greater size and complexity of software being produced compared to the 1970s. There can be no surprise that security problems are common: the field of software engineering is using something outdated and primitive for the situation, which is source code that is written and edited in plain text. Word processing went beyond monospaced type but computer code did not follow. Too many software engineers have come to believe that this is because there is something timeless about .TXT for writing code. But there is actually an opposite trend unfolding today. There is a slow movement away from from the limitations .TXT imposes, towards presentations of code that can grapple with growing software complexity. There is no need to hold onto notions that .TXT is synonymous with code; in practice, the unrecognized fact is that text is now re-interpreted by IDEs and code editors to make it feel more modern, as if it can provide the GUI features that a structured data document or application document would naturally support. Even though computer code remains a basic stream of characters, code editors are trying to make it behave as if it has been modernized. Plain text has been stretched far beyond its natural limits. All recent trends in software development environments are seeking this outcome, which is the modernization of code's interactivity by placing IDE functional veneer on top of plain text. Instead of upgrading the file format of code underneath, to structured data, so that it inherently supports these features, plain text is instead declared as unsurpassable and these extra IDE features placed on top.
Of course the software engineers instinctively seek an upgrade to code's interactivity, as they are using code in larger volumes and in more challenging ways than in previous decades. When IDE vendors add features to code editors with elaborate strategies to make interactivity work for plain text, they resist acknowledging what a contraption they have built now. What they need to do is going beyond .TXT to an application document and make this a campaign. When code's file format is upgraded, advanced interactivity will be providable in a proper way, which then will open the door to improved forms of code and programming systems. The software engineering community is not awakening to the absurdity of the situation that this is plain text from the 1970s and it should never be treated as if it naturally supports features beyond the insertion of type.
Initially, the upgrades were just about coloring the text in the early 1990s. Now there are interactive, collapsible code sections and generated image maps of the file. The notebook code editors (e.g. Jupyter Notebook) intended for data science and developing AI place the Python programming language (plain text) into an interactive format, providing an input prompt with graphical output responses, but this is actually just a well-constructed set of workarounds for inherent limitations; Python itself has not been upgraded to behave like this and it doesn't normally support this usage. All the same, after this upgrade to Python code was implemented, the interactive code notebook became an essential tool of the AI community. It is a demonstration that when code's form is actually upgraded, even in this superficial way, the results will provide immense benefits. It's just that these notebooks came about indirectly as a result of specific objectives; the people working in data science just wanted Python to behave in a certain way for their own particular needs and they weren't thinking about the broader implications, which is that if they want Python to behave in a more interactive way and also produce graphical output they have actually run up against the walls of how typewritten code has conventionally existed for making and sketching out software. The notebook code editors (e.g. Jupyter Notebook) intended for data science and developing AI place the Python programming language (plain text) into an interactive format, providing an input prompt with graphical output responses, but this is actually just a well-constructed set of workarounds for inherent limitations; Python itself has not been upgraded to behave like this and it doesn't normally support this usage. All the same, after this upgrade to Python code was implemented, the interactive code notebook became an essential tool of the AI community. It is a demonstration that when code's form is actually upgraded, even in this superficial way, the results will provide immense benefits. It's just that these notebooks came about indirectly as a result of specific objectives; the people working in data science just wanted Python to behave in a certain way for their own particular needs and they weren't thinking about the broader implications, which is that if they want Python to behave in a more interactive way and also produce graphical output they have actually run up against the walls of how typewritten code has conventionally existed for making and sketching out software.
Meanwhile, in mainstream software development, IDEs are increasingly providing enhancements to code that improve its interactive capabilities as well, to provide greater control and navigation. But to do this, they have to project non-existent structure onto the plain text (.TXT) code for the benefit of the user: they analyze it constantly in the background to make collapsible code sections with GUI arrow controls, they generate dropdown menus at the top of the window with organized sections of the file's contents, and they display code completion popover windows. They extracted this information by processing a basic file of plain text. In other words, the common IDE has begun to treat a single file of code (.TXT) as a conventional application document (e.g. XML) in the last decade, which is a very hacky activity, but the phenomenon is happening in an unrecognized way and it is a reaction to the growing problem that .TXT does not scale for larger amounts of code. The code editor undertakes user interface gymnastics with this stream of ASCII characters to implement all of the modern code editing features that appeared (such as the mini maps that now sit to the side) and when those features are added they are a consequence of how code is more complex than before. This is why there has to be a retrofitting, like placing beams and columns in an old building. That retrofitting would be, to begin with, the onscreen rendering of current code syntax as it looks today by parsing files made out of XML or other markup, to replace .TXT.
The most honest picture of how code exists today is available by opening up a file in a basic text editor like Microsoft's Notepad. Everything else code can offer the software engineer today that is interactive is actually a hack placed on top, including keyword coloring (ASCII-based code, of course, provides no coloring data in the plain text file data). IDEs and the software engineering community are avoiding the most important task a software engineer would take up in any other situation, which is to move up to an application document file format for each file of code. Otherwise, the bizarre advances continue to play out, the hot-rodding of .TXT just to keep it around the primary medium of computer programming because programmers are worried that a substantial upgrade won't fit into what exists now. As we just said though, from the outset nothing has to change that will break how people write software because it will start with just a conversion from .TXT to an XML-based (or other markup document).
When computer code's file format is upgraded to a document file format— comprised of markup like XML— and the contents are rendered inside the code editor from the XML (no different from how a web page is rendered from its HTML), the capabilities available to the programming language designers will become much broader, in many directions, from lines of code that contain multiple rows to diagrams that describe complex processes. They won't necessarily start by changing code in dramatic ways but they will actually be able to do that. It will be possible to mix node-based programming and procedural code inside the same document, which is valuable flexibility for the programmer. There will be a meaningful job for the graphic designer to assist in the layout and appearance of code documents, for the first time. A file of code will inherently permit generating more than one representation of its data because its data is made out of markup, but this will be natural to implement whereas it would be rough job to make this for today's .TXT-based code.
Many benefits will emerge when code is finally converted to a formal document format from the ground up, in many different areas, including a leap in parseability by the compilers and the IDEs, as they will be parsing structured data like XML instead of plain text. Plain text carries much ambiguity for live parsing of code and so the analyzers are not always accurate when just one character is off; deleting just one curly brace can totally confuse the compiler. When code is finally translated into a document format, which will support a live review of code naturally, the quality of users' experience with code will improve greatly and most typographic mistakes will be preventable that halt compilation (such as deleting a single character or omitting a semicolon). Many features will become feasible that no one would want to try with plain text today, such as the ability to survey a project of code in the form of a map or schematics overview. It will be possible to zoom in and out of code just like CAD because the code files will have formal structure inside them.
Especially if the code files are made out of XML, the ability to add attributes to the underlying markup will take computer programming languages to a new level. Whatever someone wants to render from the XML will specify what code can do, not merely what is typed out one text character at a time. A function will not just show up in the markup as <function> but allow the insertion of custom attributes inside the <function> XML element that provide for much broader configuration, rendered for the programmer code file. In addition, an individual line of code will be more powerful because it can contain more complex statements, permitting math notation, A section of the document can be made out of graphical components and even allowing interactive controls natively. Assigning array object variables to interactive data tables will be possible and this is something people need today. A 3D object will be assignable to a 3D model viewer displaying the object inside the line of code. An object variable with many settings will be assignable to a tab view control that has many configuration parameters for that object and it will appear that with GUI settings inside the document, in the line of code. A spline object variable will be assignable to a spline editor control, where it can be edited inside the line of code. In the future, the programmer would be able to supply his own editors like this.
The upgrade of code's file format means that many scenarios will be easily described in terms of conditions, rules, states, etc. because computer code's presentation capabilities will exist beyond .TXT. With all of these newer features provided in code, existing software in use will be relatively easy and fast to rewrite and when they are redone they will have more available in them.
Resistance to changing the file format of code and modernizing it often comes out of a lack of understanding of the problems that result from keeping .TXT as the file format today, and addressing that starts with some discussion about graphic design, a topic hardly ever paired with software engineering. For the graphic designer, though not necessarily the software engineer, once today's computer code is revealed as completely tied to the raw .TXT file format, all of the feature differences discussed among the programming languages are taking place inside a tiny frame of view, which is what can be typed into the .TXT file format, a sequence of ASCII or Unicode characters. The graphic designer knows immediately how limiting this is because, to begin with, the means of dividing information on the page amounts to manually-typed line breaks, white space (tabs and spacebar), and nothing more. Consider that in some programming languages, functions start and end with the keywords "define" and "end" while in most others (C++, Java, C#) there are beginning and ending curly braces. To the graphic designer, all of this is using typographic characters to establish box boundaries. The result is a mess of curly braces scattered down the page. The only provided way to keep code tidy is through the tab key and this has no effect on how challenging it can be to track all of the nested curly braces and parentheses. It's too primitive of a situation. There is only a vertical division of information (line breaks between sections of code) in plain text, and nothing can flow horizontally.
In a programming language that is not constrained by .TXT, there will be no typing out of beginning and ending curly braces just to establish the box boundaries of a body of code. This a task the software engineer shouldn't have to deal with, the maintenance of box boundaries. Instead, the contents of a function (or other code section) will be enclosed in a graphical, bordered box, as the file of text will no longer be .TXT but rendered from a document format (e.g. rendered from XML). The bordered boxes (the containers for sections of code) will not only flow vertically as in plain text but will be flowable horizontally at the same time, like how a magazine layout has multiple columns. At that point, the focus of the user interface will move away from simple typing to a more complex dynamic. It will involve making use of interactive keyboard commands to control the layout and insertion of code, not typing out '{' or '}', and the IDE will begin to resemble a media production app, like a vector-drawing program or animation program, because the code will be modernized; the code document will offer modern software capabilities. The user interface principles will have to be more sophisticated than what is currently used for code, which is typing, and so discussed on this page are the bimodal control UI and other user interface concepts such as Noctivagous' npsurfer web browsing extension that demonstrates a UI for accessing a certain section of the screen quickly without the mouse. In short, future code interactivity should not rely on the mouse unless the mouse is used as part of the bimodal control UI. Reluctance to upgrading code is also frequently a result of apprehension by software engineers that the clicking mouse will be the focus instead of the much faster keyboard, which shows its strengths in the classic command line interface.
The replacement of curly brace characters with bordered boxes brings with it broad-ranging opportunities in other areas of code and what a document of code can offer the software engineer, including interactive components in a line of code that have a lot of power and configuration built in. Promisingly, it opens the possibility of customization of the programming language itself; the ability to add features to the code document (through scripting and descriptions) will naturally make sense as a feature of programming, far more than if the code is plain text. The software engineer will be able to program his own interactive components that make up a line of code, tailored for his own project if necessary.
Just this one change demonstrates how the features of any mainstream programming language are currently severely confined to what the .TXT file format provides, as .TXT cannot draw graphical boxes and so it cannot draw anything else and is stuck in the early days of mainframe computing. Speaking within the constraints of that primitive file format, it is a debate about what characters should define the bounds of a function (will it be curly braces, line breaks, or keywords?) and all similar personal preferences, such as whether a line should end in semicolon. But that kind of debate disappears when it is a graphical box enclosing the contents of a function. When a line of code is rendered from XML it doesn't need to have semicolons terminating it. Omitting a semicolon or removing a single curly brace won't break the entire project of code, as is currently the case.
Thus, the design decisions that differentiate one programming language from another actually just exist within this limited and ubiquitous file format, plain text. Since it is so restrictive, having no structured data inside it and being a 1:1 monospaced rendering of the data contents of the file, what is actually the case is that the feature differences between programming languages are rather miniscule compared to the open vista that a document format will provide. The mainstream programming languages all currently exist within what characters .TXT accepts, but a document format will extend far beyond lines of monospaced, typewritten characters. A programming language can someday manifest as anything that involves a more graphical and interactive dynamic: it can include semiotical diagrams, images, multimedia, and a line of code can branch out into multiple lines. Importantly, the organization of the information on the page will finally include graphic design layout, with a more compact and readable distribution of information, resulting in far less scrolling.
To the graphic designer it is deeply problematic that computer code
always looks like an undifferentiated mass of multi-colored ASCII
keywords, something exotic-looking to the lay public but actually
mundane. When a code document, with markup underneath, is the medium,
the process of entering code might continue to emphasize typing out text
characters but the end result, after a given code keyword, command, or
instruction is completed (not just “func” but also “pop”, “push”, etc.),
would be transformed in the code document so that every keyword is
provided its own unique symbol. An image variable referenced in the
code will always have a symbol of an image to its left
(🖼️imageVar) . The document would be far more legible at a
glance with this one change. Every variable and object type present in
the code should have a symbol preceding its typewritten name so that the
page of code is legible at a glance. Different sections of code should
be colored by their categories, displaying distinctive font and styled
box boundaries. This is the sort of priority a typical software
engineering team wouldn’t normally take on and it demonstrates the
importance of emphasizing graphic design for the future of computer code
and programming.
The Inclusion of External Physical Controls
Code editors and IDEs have remained largely the same in appearance for decades, but now it makes sense for the programmer in the office to use hardware to interact with the IDE and insert code, regarding the situation as the same as how a video editor buys control decks. At a minimum, Noctivagous suggests using one or more touchscreen computers, such as an iPad, set up next to the programmer's computer so that he or she can make use of a custom onscreen grid of buttons that insert common code snippets and templates for functions, classes, loops, branching statements, variables of various types, etc.
JIT-Focused Software Development
On another topic in software engineering, the work processes and what dynamic should be emphasized, it's also important to note that many software applications today could be written in a live programming environment making use of JIT compilation, but for some reason this is only treated by the computing industry as relevant for a web app. Many complex apps written for the web are fully ready for use as soon as "reload" is executed in a web browser, and this is in stark contrast to the inconvenience of compiling AOT (ahead-of-time compiled) code for equivalent apps in desktop and mobile software development. Something should be done to bring this JIT dynamic into mainstream software engineering as the central activity so that at least the software is developed in real time but it can be compiled conventionally for optimization at the very end. For instance, a calendar software application is very lightweight for today's computers, and there is no reason that an application like that would need to be written in code that has to be recompiled after every change. But the tools offered for web development, where live programming is most possible, are too undeveloped to replace conventional software engineering. A calendar app is so lightweight that its code and user interface could be written and modified while it is opened, in a situation even better than reloading a web page. The mindset of the software engineering community did not catch up with the major increase in computing processing power, the gains that were provided to JIT compilers as a result, and software applications today are written in a style that is a holdover of the slower machines of the 1990s. With web apps today, they can be edited and then reloaded immediately, whereas the same app in an IDE may take 30 seconds or more to be recompiled. Of course, in the 1970s the original goal of Smalltalk-80 was to allow the programmer to edit the software in real time and that is what it could do. Other programming languages didn't adopt that feature, but now they can more easily than ever. For many types of apps, their functionality could be assembled and edited by the software engineer live because they only have certain functions that are processing intensive. GUI is always lightweight for today's machines, but it wasn't for computers of the 1990s. That is why large software applications could be sketched out and filled in during an execution mode. Many professional apps could have their foundation assembled in real time. Instead, any app has to be rebuilt (recompiled) unless it is a web app made out of JavaScript, because JIT code editing not been made a priority for mainstream software development.
On another topic, the traditional UNIX command line interface also needs an upgrade because when long sequences of logs and operations occur, they fly by so fast that they are completely unreadable, which often makes the situation absurd and pointless. Take for example that the command line, the line where commands are entered, is entirely a vestige of the 1970s screens because it exist as part of the terminal output, displayed inside the overall grid of monospaced characters. Since GUI is available, the command line can be separated from the output viewport and made its own text area, which has been the case for CAD programs for a long time. Then, what is the terminal output area? It no longer has to be confined to a VT100 emulation, a grid of ASCII characters. It can be redesigned to include graphics.
The command line should at least be upgraded such that graphical progress bars appear inside the terminal window when operations are taking place, and all terminal software should be graphics capable; they should be able to show thumbnails of images inside the terminal window after a command is executed, capable of showing them in a grid while listing a directory for example. A terminal should be able to play videos too, even 5 at a time simultaneously. Many aspects of the UNIX era should be upgraded. Addressing the problem of a stream of unreadable logs that quickly passes by: all log entires should declare their category or purpose so they are grouped into boxes as they show up in the terminal. Moreover, these boxes should appear in multi-column format.
-
Future Code Requires The Integration of Graphic Design into Software Development Environments
-
Opportunities to Upgrade Computer Code’s Form inside The Editor
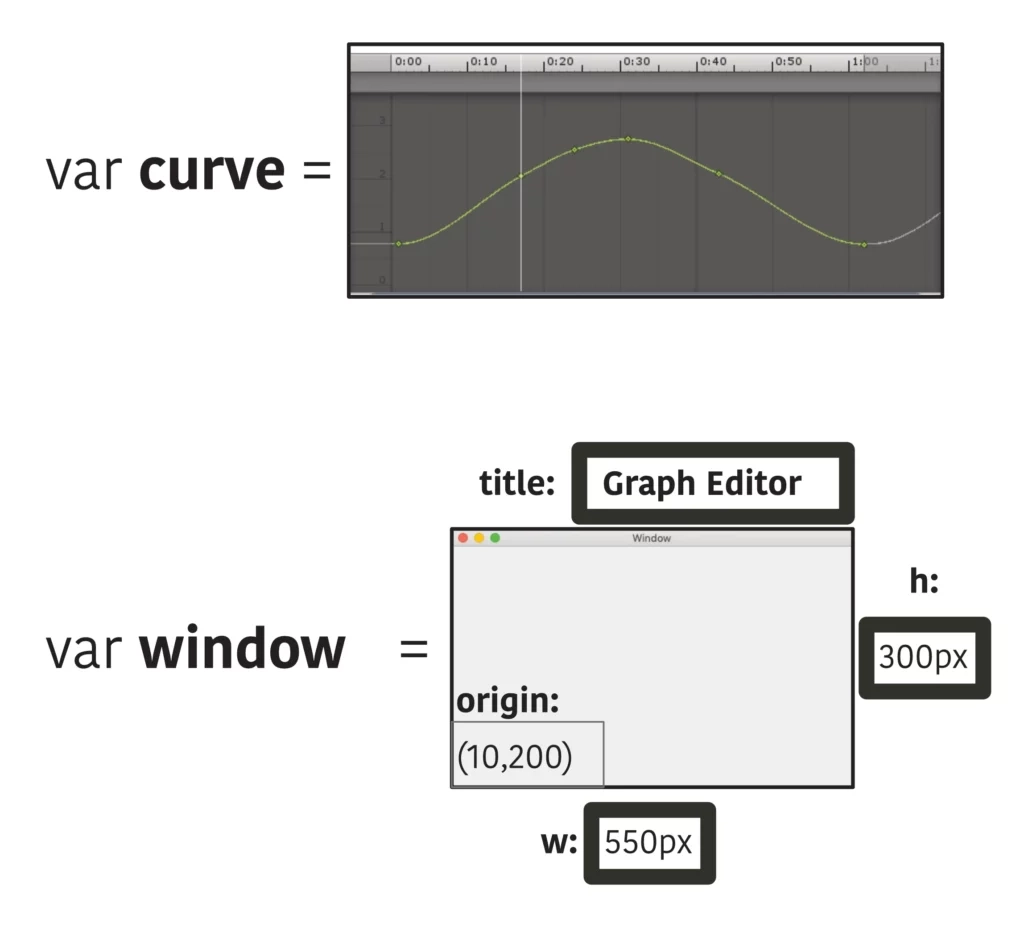
Programming languages designed for application software development are more capable than a few decades ago, but not by much. Any progress has occurred inside the plain text file format. They haven't been upgraded in a comprehensive way that utilizes the new graphical capabilities of computers. It's all terminal type. To give an illustrative example that adds to the two shown above, an object variable should be assignable to an interactive vector field in the code editor. A UI control embedded in a line of code can do much more than alphanumeric type in complex situations, across a wide range of subjects. Instructions can someday be expressed semiotically, even, if graphics are embraced as elements inside a line of code. So far, there has never been a semiotical programming language system.
When graphics are included, the resulting depth of command over the operations of a computer will not be matched by any current sequence of plain text. Small experiments have shown that this is much superior, it's just that there are doubts expressed by some over whether it can match the speed of editing plain text— in other words the user interface. We address this here. What seems like an insurmountable obstacle, making graphical code's interface comparable to plain text in editing power, is actually a matter of taking a different approach. In every single case, previous attempts abandoned too much of what was in active use in the practice of programming inside plain text and tried to come up with something foreign, which means that the code conventions did not match what people were trying to do when they program. Instead, Noctivagous' plan is to gradually add augmentations to plain text as it exists today. A little bit later, code can break free from plain text and sit inside its own document file format. (Already there are movements in this direction with Jupyter Notebook, just not for the code itself, only the output.) So, initially it is that UI and widgets additions are allowed inside a line of plain text code, just like right now when a color can be assigned to a color picker control. After a color picker has been used in code for a while, it is felt as missing when not available. In this way, graphical widgets and controls won't only be a matter of convenience. When they are placed into code, they will be able to summarize large sequences of computer instructions such that no one will want to go backwards to just typing out regular terminal type (monospaced type).
The importance of this effort can be explained in the following. Producing a competing web browser engine that is as complete as Chromium or WebKit can't be done in a short period of time, and when this isn't possible it represents a dead end for software development. Those two software projects will never be unseated because there is little incentive to surpass them, as what is written from scratch with current programming languages will basically end up being the same in outcome. Even with AI programming assistants, this does not change because those engines have reached the ceiling of what plain text code will produce without an upgrade.
It is possible to escape this dead end and it is by breaking from the fusion of computer code to the typewriter. For a major upgrade to happen, alterations like the above image have to occur, because code has to look more like the software it produces, not just raw, monospaced type. It has to be able to express complex operations in terms of signs and symbol someday. Computer science mindsets that refuse collaboration with graphic design won't suffice, then, as software development has stayed inside terminal type all this time. When code is upgraded, the initial subjects of concern turn out to be different; they will have to incorporate graphic design and media design principles. The areas of expertise involved are often outside of what is found in mainstream software engineering discussions.As explained in the articles on this page, the obstacle to a deeper level of progress in software development is the confining, primitive offerings of the file format plain text, that it has been stretched far beyond its bare capabilities to serve increasingly large and complex needs, blowing past the environment of 1980s and 1990s computing when it formed the programming languages still in active use today, like C++, Python, and Java. This primitive code medium is largely accidental, it doesn't lend itself to a surveyable view, a zoomable map like CAD, and it of course by definition cannot accommodate rich text inside the code without odd adaptations. Since it has so many limitations for today's world, it has to be transcended.
A collection like an array or dictionary is still not editable by way of a data table GUI control inside a line of code. Instead, the programmer clumsily navigates through commas with the arrow keys. In addition to this, future computer code needs to be editable in multiple newspaper-like columns to make efficient use of screen space. Plain text is too raw of a file format for programming software in the 21st century, and it doesn't allow inclusion of modern GUI controls for formulating groups of instructions.
Noctivagous starts with the plain text code as programmers work with it today and then adds GUI to that as the first step, continuing the trend of exists today where the value of a color variable is controllable by an inline color picker. It is believed that later the code file should be transformed into a document file format for truly rich code editing. Each article below explains these issues.
-
The Upgrade of User Interface
- The Bimodal UI Theory (Demo)
- It’s Difficult for Users to Organize Files on Computers When Provided a Such a Basic File Tree Hierarchy.
-
Connect Some Windows with Node Wires If You Like. Software
Applications Now Operate In Isolation From One Another.
Noctivagous will let you wire up application windows as if they are nodes in node-based programming, because the input and outputs will be on the back of the window and it can flip around. Different applications will interact with each other, providing their complex features to each other, publishing and receiving data as the user decides.
- Moving Past The iOS And Android Touchscreen User Interface
AI
- AI Facilitation of Work
Processes Vs. AI Takeover of Human Jobs
Discussing What Should Be The Aim for AI Technology, Using The Example of a Vegetable-Cutting Kitchen Appliance That Is Driven by AI
- AI Facilitation of Work
Processes Vs. AI Takeover of Human Jobs
Graphics And File Formats